Parallel Computing pada Clustering K-Means untuk Analisis Keketatan Program Studi SNBT 2023
DOI:
https://doi.org/10.34010/hpm5tg52Abstract
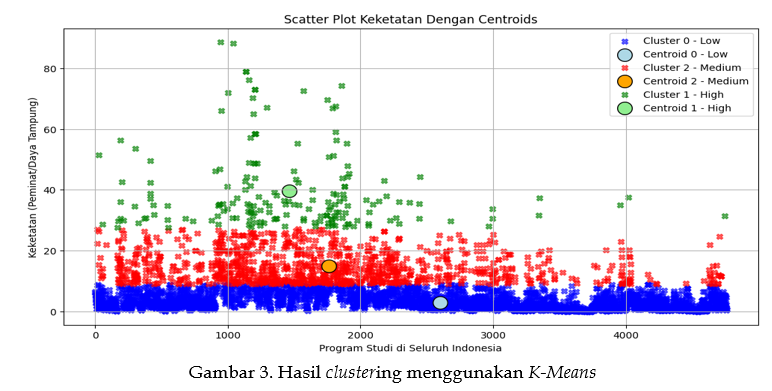
This study aims to analyze the competitiveness of study programs in the 2023 SNBT dataset using the Knowledge Discovery in Databases (KDD) method and the K-Means Clustering algorithm. The competitiveness of study programs is measured by the ratio between the number of applicants and available slots, reflecting the level of competition and popularity of the programs. Two main issues are addressed: the urgency of data-driven decision-making for formulating effective student admission policies and the lengthy execution time on large datasets such as the 2023 SNBT data, which includes thousands of study programs with complex variables. The number of clusters was determined using the elbow method, dividing the data into three categories: low, medium, and high. Clustering evaluation was conducted using the silhouette score metric, revealing that Cluster 0 (low) demonstrated the best quality with the highest silhouette score. To accelerate the analysis process, parallel computing was implemented using the joblib, scikit learn and multiprocessing library, significantly reducing execution time compared to conventional methods. With an average silhouette score of 0.684816, the results indicate good clustering quality. These findings provide valuable insights for universities in understanding the competitiveness patterns of study programs and support the development of more effective and efficient data-driven student admission policies.References
[1] Sekar Setyaningtyas, B. Indarmawan Nugroho, and Z. Arif, “Tinjauan Pustaka Sistematis: Penerapan Data Mining Teknik Clustering Algoritma K-Means,” J. Teknoif Tek. Inform. Inst. Teknol. Padang, vol. 10, no. 2, pp. 52–61, 2022, doi: 10.21063/jtif.2022.v10.2.52-61.
[2] A. Septiarini, I. A. Thaher, and N. Puspitasari, “Pengelompokan Kualitas Kinerja Pegawai Menggunakan Metode K-Means Clustering,” Komputika J. Sist. Komput., vol. 11, no. 2, pp. 131–141, 2022.
[3] Q. A’yuni, A. Nazir, L. Handayani, and I. Afrianty, “Penerapan Algoritma K-Means Clustering untuk Mengetahui Pola Penerima Beasiswa Bank Indonesia (BI),” J. Comput. Syst. Informatics, vol. 4, no. 3, pp. 530–539, 2023.
[4] M. Azzam Al Fauzie and J. Akhir Putra, “Clustering Data Menggunakan Metode K-Means untuk Rekomendasikan Pembelajaran Akademik bagi Siswa Aktif dalam Ekstrakurikuler,” KLIK Kaji. Ilm. Inform. dan Komput., vol. 4, no. 1, pp. 642–648, 2023, doi: 10.30865/klik.v4i1.1116.
[5] Haris Kurniawan, Sarjon Defit, and Sumijan, “Data Mining Menggunakan Metode K-Means Clustering Untuk Menentukan Besaran Uang Kuliah Tunggal,” J. Appl. Comput. Sci. Technol., vol. 1, no. 2, pp. 80–89, 2020, doi: 10.52158/jacost.v1i2.102.
[6] Miliani, Dwi Fitri, and Wawan Joko Pranoto. "PENERAPAN K-MEANS CLUSTER DALAM MEMILIH STRATEGI PROMOSI PENERIMAAN MAHASISWA BARU." Jurnal Cahaya Mandalika ISSN 2721-4796 (online) (2024): 1665-1676.
[7] F. Nurdiyansyah and I. Akbar, “Implementasi Algoritma K-Means untuk Menentukan Persediaan Barang pada Poultry Shop,” J. Teknol. dan Manaj. Inform., vol. 7, no. 2, pp. 86–94, 2021.
[8] D. Damayanti, “Implementasi Algoritma C4. 5 Prediksi Produksi Komoditas Tanaman Perkebunan Berdasarkan Luas Lahan,” Tin Terap. Inform. Nusant., vol. 2, no. 10, pp. 571–579, 2022.
[9] A. Asmana, Y. A. Wijaya, and M. Martanto, “Clustering data calon siswa baru menggunakan metode K-Means di sekolah menengah kejuruan wahidin kota cirebon,” JATI (Jurnal Mhs. Tek. Inform., vol. 6, no. 2, pp. 552–559, 2022.
[10] H. A. Yanti, “Pengolahan data sederhana menggunakan R STUDIO,” Sienna, vol. 2, no. 1, pp. 1–9, 2021.
[11] F. Alghifari and D. Juardi, “Penerapan Data Mining Pada Penjualan Makanan dan Minuman Menggunakan Metode Algoritma Na{"i}ve Bayes: Studi Kasus: Makan Barbeque Sepuasnya,” J. Ilm. Inform., vol. 9, no. 02, pp. 75–81, 2021.
[12] S. Pujiono, R. Astuti, and F. M. Basysyar, “Implementasi Data Mining Untuk Menentukan Pola Penjualan Produk Menggunakan Algoritma K-Means Clustering,” JATI (Jurnal Mhs. Tek. Inform., vol. 8, no. 1, pp. 615–620, 2024.
[13] M. R. Alhapizi, M. Nasir, and I. Effendy, “Penerapan Data Mining Menggunakan Algoritma K-Means Clustering Untuk Menentukan Strategi Promosi Mahasiswa Baru Universitas Bina Darma Palembang,” J. Softw. Eng. Ampera, vol. 1, no. 1, pp. 1–14, 2020.
[14] A. Fira, C. Rozikin, G. Garno, and others, “Komparasi Algoritma K-Means dan K-Medoids Untuk Pengelompokkan Penyebaran Covid-19 di Indonesia,” J. Appl. Informatics Comput., vol. 5, no. 2, pp. 133–138, 2021.
[15] S. Hendrawan, F. K. Sari Dewi, and Pranowo, “Clustering Evaluasi Dosen Universitas Atma Jaya Yogyakarta Menggunakan Metode K-Means,” J. Inform. Atma Jogja, vol. 4, no. 1, pp. 1–8, 2023, doi: 10.24002/jiaj.v4i1.7436.